Tech Deployments
Senior AI Systems Engineer & Technical Project Lead, especializado en infraestructuras de IA y datos de producción, desde ingestion y orchestration hasta analytics, deployment y automation a escala.
🧩 Data Infrastructure
- Construí un sistema de orquestación end-to-end: un scheduler modular que supervisa 100+ workflows ETL y ML con logging tipo CI, monitoring y recovery ante fallos.
- Diseñé Textflow ETL y arquitectura de memoria: pipelines JSONL/Parquet que alimentan capas de retrieval basadas en FAISS; incluye data validation, lineage tracking y summarization.
- Desplegué ChromaDB como knowledge store: sistema persistente de embeddings con retraining automático, APIs de consulta y versionado de metadata.
- Integré un stack multimodal de datos: ingestion unificada de audio, video, OCR y texto estructurado en datasets reproducibles y validados por schema.
- Automatizé framework para datos financieros: motor de OCR y parsing que reconcilia facturas y ledgers con trazabilidad de auditoría y dashboards analíticos.
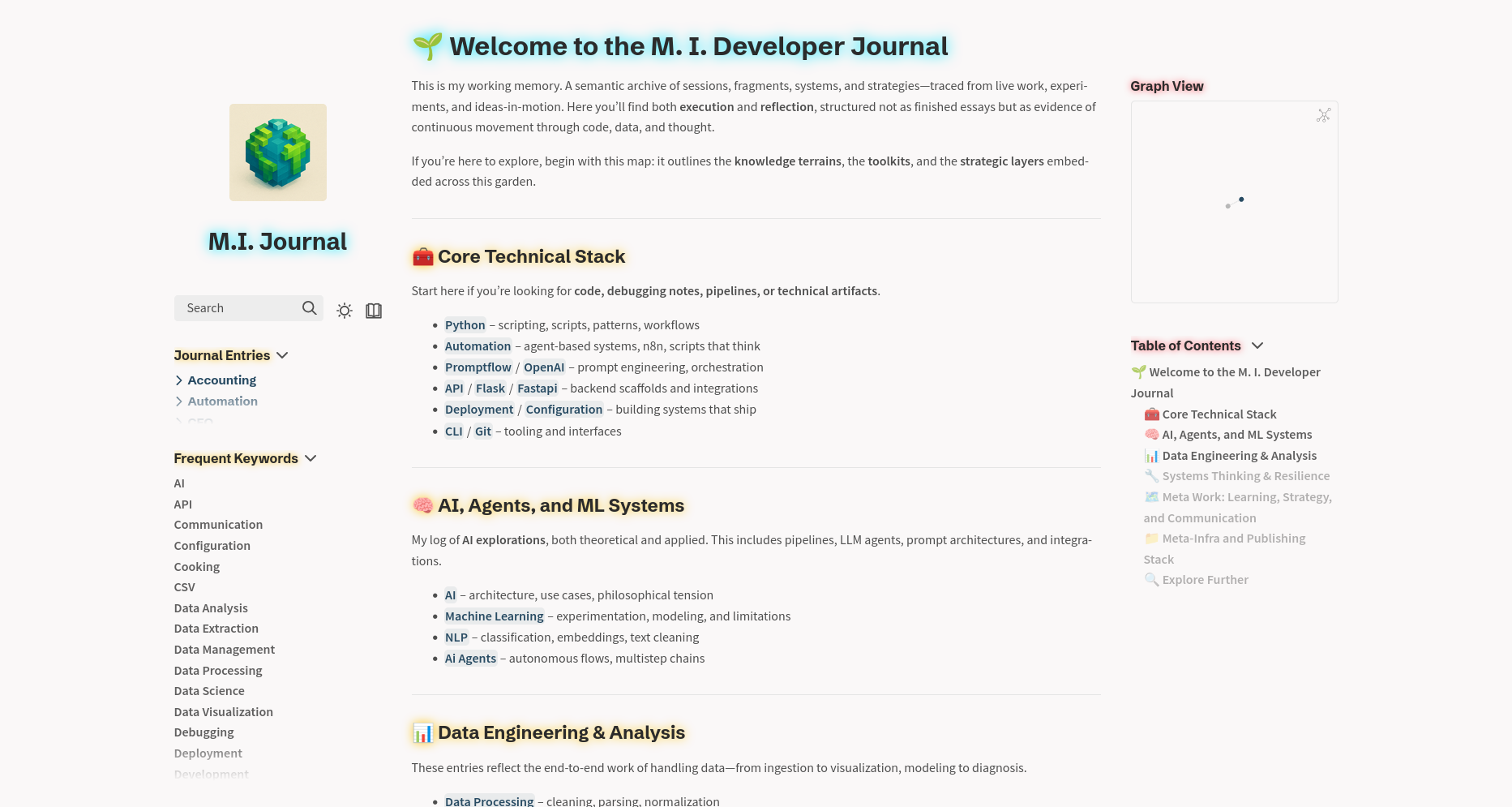
Deployment: M.I. Journal
Knowledge hub tipo Quartz con tags, logs mensuales y navegación semántica.
🧠 Machine-Learning & Knowledge Systems
- Diseñé un engine de entidades y grafo semántico: pipelines NER → knowledge-graph que potencian analytics cross-document y search.
- Implementé un Repository Intelligence Toolkit: scripts CI y analíticas via GitHub API para dependency audits, code-health metrics y workflow telemetry.
- Armé entornos analíticos cloud-linked: integración con BigQuery y GCP storage para modelado socioeconómico; pulls y transforms automatizados.
⚙️ Automation & Governance
- Desarrollé pipelines de deployment para sitios estáticos y APIs: builds continuos Markdown→web y endpoints JSON para outputs analíticos.
- Arquitecté un framework de consultoría en IA y automation: producticé el stack interno de automatización en microservicios modulares con lógica de paywall y dashboards.
- Mantengo la capa de documentación Control-Tower: ADRs y runbooks que registran decisions arquitectónicas y ciclos de vida operativos.
🤝 Collaboration & Learning Tools
- Creé una capa de colaboración cross-team: CRM + CMS que convierten datasets y outputs de investigación en dashboards accesibles para partners no técnicos.
- Generé materiales pedagógicos auto-generados: notebooks y ejemplos derivados de repos vivos, asegurando reproducibilidad para teaching y docs.
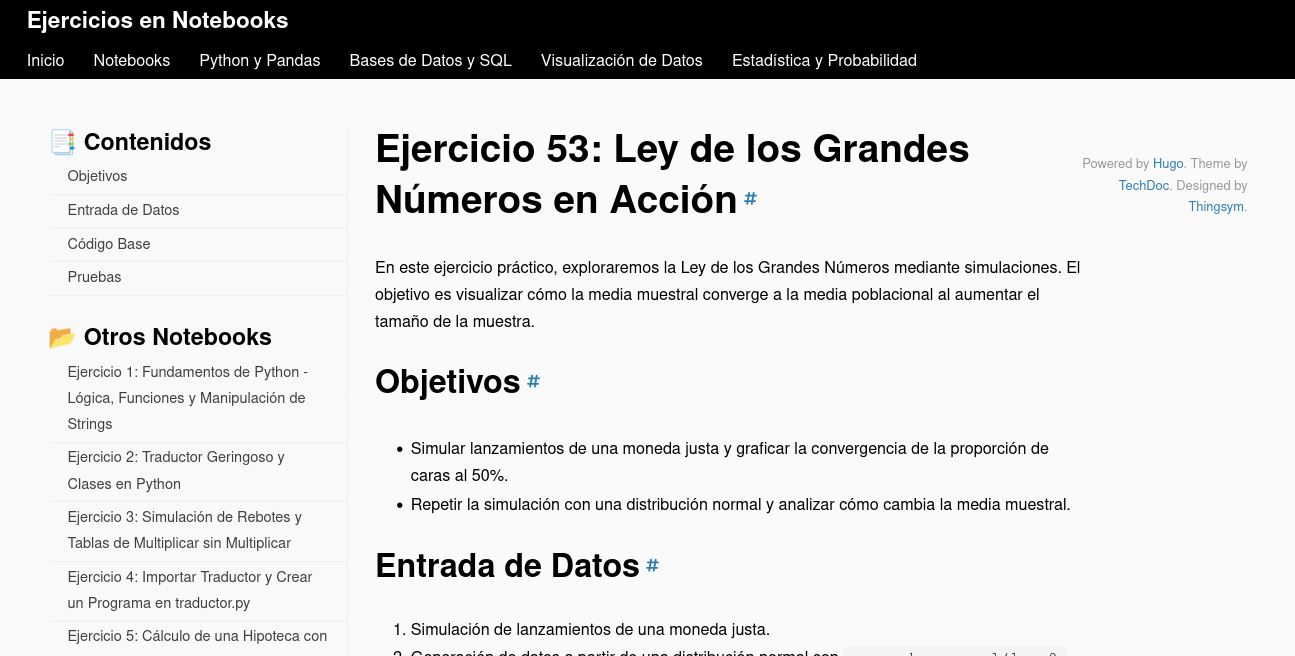
Deployment: LDD-NBS Course Exercises
Ejercicios basados en notebooks para el Data Lab de la UBA, pensados para aprendizaje reproducible.
- Desplegué sistemas de Question-Answering: apps basadas en LLM para retrieval interno de conocimiento y asistencia docente.
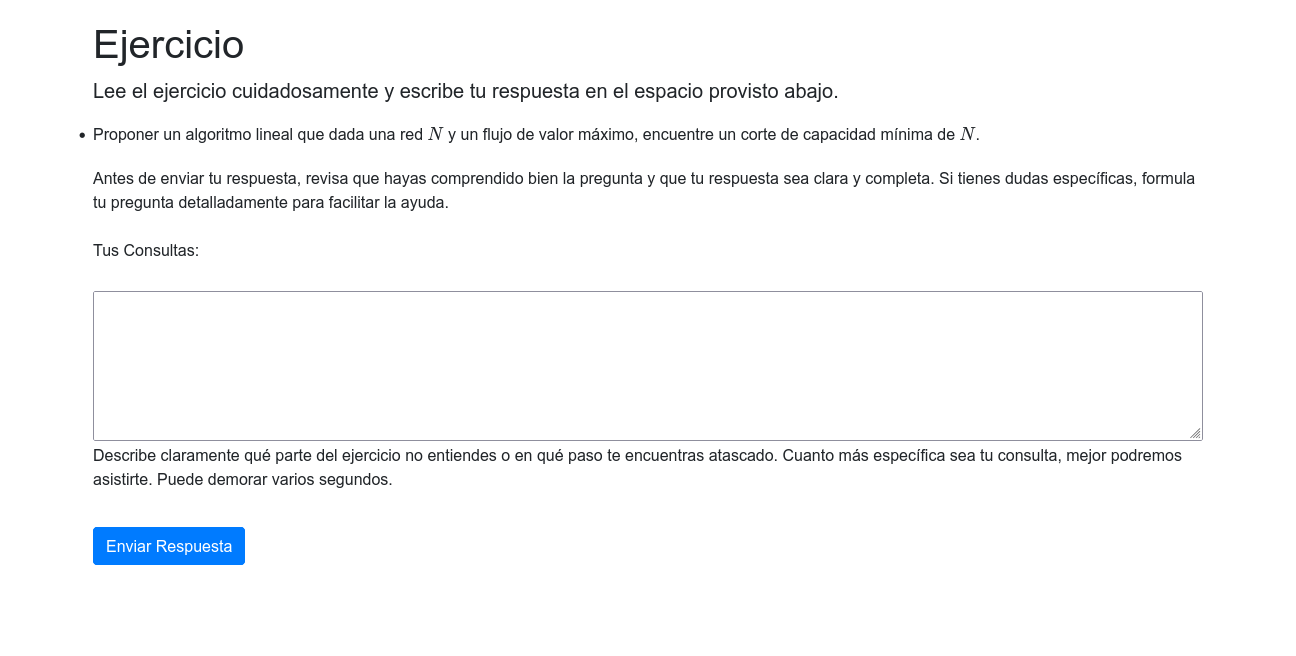
Deployment: Evaluar App
Distribución de ejercicios asistida por IA y feedback para cursos departamentales.
Competencias clave: Python, SQL, ChromaDB, FAISS, Docker, orquestación estilo Airflow, BigQuery, GitHub Actions, pipelines OCR y diseño de data governance.
Áreas de foco: fiabilidad en automation, arquitectura semántica de datos y ecosistemas analíticos reproducibles.